
Introduction
In this module students will learn about regular expressions. What they are in theory and in practice, as well as how to use them to search and navigate digital texts.
Given the complexity of regular expressions, with various implementations, subtle differences, and extensions, the main learning goals are to familiarize students with the overall forms, and what it means to use them as search tools (in contrast to exact match searches). Emphasis is on basic theory as it helps students from being overwhelmed by the variations that exist in practice. In particular, one major learning goal is to introduce the idea of navigational critical thinking, and that there is a connection between describing a structure and being able to navigate it.
Some Question to Ask Yourself
- What does it mean to navigate?
- How do we build words? How does this relate to navigation?
- How do we search for all the grammatical variations (conjugations, inflections, etc.) of a word?
The computer activities in this module use the Bash shell, along with find, grep, sed tools to implement regular expression searches. The challenge at the end of the demonstration section offers an effective computer activity.
This module introduces regular expressions, a powerful tool that can help search for patterns of words in text such as source code or database files.
Learning Style
How do you learn? I will explain my way:
The Land, and The Landscape.
When I arrive at a land I’ve never been to before, I explore, I search, I navigate, and eventually I build a map in my mind. This is how I learn new lands. Territories of knowledge are no different: they are landscapes of information. I navigate, or use references if I’m already familiar with the information, otherwise if I’m lost or I don’t yet have a map in my mind, I instead search and explore the area to orient and reorient myself.
This is my way of learning. What’s yours?
Information Landscapes
In this changing world we have new technologies, new realities such as virtual reality or augmented reality, as well as the Internet, which all contain places to visit and explore. These territories of information are vast, so how do we navigate them?
It’s a rather overwhelming question, isn’t it? When such confusion or complexity arises, I find it helpful to simplify the problem. Let’s get rid of the clutter of details, keep things simple, and talk a little about basic navigation itself.
When we navigate the land, even if we’re in an urban environment, what is our approach? We could use GPS, Internet apps, or even ‘old fashioned’ paper maps. Better yet, have you heard of Ammassalik wooden maps?
(Source)
Inuit ancestors in Greenland used these carved wooden maps when they travelled by boat. If you drop these maps in the water they float, and aren’t ruined if they get wet. Amazing!
With all of these various strategies, it’s safe to say then there are several approaches when it comes to basic navigation. Since that’s the case, instead of looking at the differences between them, let’s find what’s common between them. What do you think? For me, what’s common is there’s always a source, a destination, and directions between. Sources and destinations are straightforward. As for directions, things are a little more complicated.
Some people like to use cardinal directions: “Head northeast until you see the lone hill with a boulder next to it, then go south.” Others prefer to use local routes: “Go left at the school, follow the road to the intersection, then turn right.” But these two methods have a commonality: both use markers. The former uses landmarks such as the “hill and boulder,” while the latter uses surrounding details such as “the school” and “the intersection.”
How then, do we traverse landscapes made of information? Landscapes such as ebooks, websites, and databases, are digital texts made up of words, numbers, and special symbols; and just as with the land, these digital landscapes are all about relationships. It’s a matter of knowing where we are within these navigational relationships, how to get where we want to go, and maybe even using an occasional marker along the way.
Why Regular Expressions?
Regular Expressions help us describe and find markers within text.
Keep in mind we don’t necessarily need regular expressions, as there is always the option of going through a text manually to find patterns of interest. But with such large quantities of information—these days known as big data—there are many occasions when a manual search is not practical. Our strategies will always remain sourced in traditional ways of navigating, but sometimes it’s good to adapt to newer approaches too.
If you’re new to regular expressions they can seem strange or awkward at first, so before I introduce them I thought I would list some additional motivation in their applications:
- Databases: Many databases let you use regular expressions to search and find information of interest. For example, you might be doing statistics or data science to help understand or take care of the animals on your Lands; regular expressions can help with that.
- Source code: As a programmer, if you write lots of code, your source becomes more difficult to maintain. When your source is made up of many files, it becomes harder to keep it all in your head, or if you make changes to the design you may get lost even though you wrote the code. Regular expressions can help find functions you’ve misplaced, or to help make sure you’ve changed all occurrences of a variable name.
- Compiler Theory: How do compilers and interpreters read source code anyway? If you ever want to explore these theories, regular expressions are the place to start. Compilers themselves start by using regular expressions to break up the source code into words, which then can be processed further.
What Are Regular Expressions?
Regular expressions are used to find patterns of words, but what does that mean?
In our daily lives we take for granted that we build words all the time. When we speak or write, we’re building words. Regular expressions can be thought of as more powerful tools allowing us greater flexibility to do the same thing. How do we build words? What tools do we have to construct words? If we’re writing a word, we start with the first letter, add the next letter, and the next, until the word is complete.
Regular Expressions let us express this too, but it also lets us express alternatives, as well as repeating patterns. We’ll get into this shortly, but once we express these constructions, the idea is that our computers will read through a text, using our rules to match the regular expression patterns. This will make sense soon enough.
Building Regular Expressions
Starting with terminology, we have three basic operations to build words:
- catenate: Regular expressions let us build words in what we would consider the “normal” way. This is called catenation. We build words by chaining letters or expressions together. Some prefer to call this “concatenation.”
- alternate: Here we build words by listing alternative expressions. Some refer to this as the “union” operation. Either way, we will write it with a bar (|) notation.
- repeat: Finally, we build words by repeating an expression. This is also known as the “star” or “closure” operator. We write this operator with a star (*) symbol.
How do these operators work? Catenation is straightforward: we just put letters or expressions next to each other in a chain. They then follow each other sequentially.
For alternation: let’s say you wanted to search an ebook for the word “qimmiq” (dog), but you know that sometimes it’s capitalized “Qimmiq.” You don’t want to miss that variation, so with regular expressions we can build this word as:
(Q|q)immiqWhen you’re listing alternatives it doesn’t matter the order you put them in. So to be clear, we could also build this word as:
(q|Q)immiqSome ebook search bars have a “case sensitive” option that does the same thing, so why use regular expressions at all then? Because sometimes we want to search for alternatives other than capitalization. For example some people or regions might spell dog as “qimmit”, so you’d want to include this alternative:
(Q|q)immi(q|t)As for repetition, the real power to express word patterns comes from using this operator. Let’s say we also want to include the plural of dog, which in English is dogs, and in the Inuit language is qimmiit. The repeat operator lets us repeat a letter or expression zero or more times. This is the most subtle operation to understand, and it might take a bit of getting used to.
So if we’re looking for the word “dog” and we want to include possibilities of capitalization, different spellings, or plural cases, then we can build this word pattern as:
(Q|q)immi*(q|t)Let’s review. We started with (Q|q)immiq. What have we done? You could say we’ve built a pattern of words, but you could also say we’ve built exactly two words:
{ Qimmiq, qimmiq }Then we extended this with alternate spellings (Q|q)immi(q|t). If we expanded the first alternatives, we would have two expressions:
{ Qimmi(q|t), qimmi(q|t) }Now, for each expression we can expand the remaining alternatives:
{ Qimmiq, Qimmit, qimmiq, qimmit }Finally, we included the plural option with the repeat operator (Q|q)immi*(q|t). This is where things get a little complicated. Our alternatives expand the same way as before:
{ Qimmi*q, Qimmi*t, qimmi*q, qimmi*t }But what does this star symbol mean exactly? Specifically, it means the letter or expression that comes before is repeated zero or more times. So for example, if we had i* as our regular expression instead, it would expand to all of the following strings:
{ empty, i, ii, iii, iiii, iiiii, … }Since it’s allowed to repeat zero times we take that to mean the string exists but is empty. Strange, huh? Truthfully, it’s a math thing like zero, it exists but is nothing.
Getting back to our (Q|q)immi*(q|t), this would expand as follows:
{
Qimmq, Qimmiq, Qimmiiq, Qimmiiiq, Qimmiiiiq, Qimmiiiiiq, Qimm…q,
Qimmt, Qimmit, Qimmiit, Qimmiiit, Qimmiiiit, Qimmiiiiit, Qimm…t,
qimmq, qimmiq, qimmiiq, qimmiiiq, qimmiiiiq, qimmiiiiiq, qimm…q,
qimmt, qimmit, qimmiit, qimmiiit, qimmiiiit, qimmiiiiit, qimm…t
}Pretty intense! Way too complicated! This is true, but it shows you the power of these tools to build not just words, but patterns of words.
This example raises another point about regular expressions: using the repeat operator not only matches against words you’re interested in, but also against words or strings you didn’t ask for. In practice, most apps or software that let you use regular expressions have ways to fix this, as we’ll see soon enough.
Finally, you may be wondering: when computers use regular expressions to find patterns in text, do they look through every single word? That’s way too many! Infinitely many when using repetition! The answer is they don’t. As mentioned previously, they follow along the text, and use the rules of the regular expression to match the string in front of them:
Text: Another word for dog is qimmiq.
(Q|q)immi*(q|t) ✅Extending the Toolset
So far I’ve introduced regular expressions as three tools to build words: catenation, alternation (|), and repetition (*). This is the theory of what regular expressions are, and it’s all that’s needed if you want to prove important theoretical results about them, but in practice they can be made more accessible.
Regular expressions have been around since the beginning, and since then programmers have added additional tools to the inventory to make them more expressive. There are many extensions, but here are the most common operators:
. (any character)
[b5'] (character classes)
[[:digit:]] (special classes)
[A-Z] (character ranges)
e{5} (exact repetition)
e{2,3} (repetition ranges)
a+ (one or more)
J? (zero or one)We’ll explore a few of these in the demonstrations.
Keep in mind that these tools only exist as conveniences. They’re not strictly required to find a given pattern, but are common enough to have been given their own (simpler) notation. For example, a+ means one or more of the letters “a.” Using original regular expressions this could be coded as aa* as it translates to: a catenation of ‘a’ followed by zero or more ‘a’s. If you think about it that just means “one or more.” As another example the expression J? means exactly zero or one. In this case it could be written it as an alternation (empty | J) using the original expressions which means the same thing.
In anycase, with these extensions, we can rewrite our earlier “plural dog” search in a more accurate way:
(Q|q)immi{1,2}(q|t)In this demonstration we are exploring some command line tools that let us use regular expressions. In particular will we look at find, grep, and sed.
Requirements
These examples use the Bash shell (command line) as part of the Ubuntu operating system. You will find Bash already installed (or easy to install) on most Linux and Mac operating systems. At the time of writing, Windows uses Powershell, but recent versions also have support for Bash.
Irregular Expressions
In practice regular expressions are often referred to as reg, regex, regexp or similar variations instead of the full “regular expressions.” We’ll do the same here. Before getting started we should also talk about basic versus extended regular expressions.
Unfortunately theory and practice don’t always align. Various software that allow the use of regexps sometimes implement them differently. For the most part it’s similar enough, but it’s a good idea to look up the documentation or find cheat sheets before using them. In the Bash examples presented here, basic expressions as well as extended expressions are the same except for how they use the backslash (\) character.
The main issue is this: let’s say you want to use the regex “The seal watch(ed|s) observantly.” The problem is, what did we mean when we added the period at the end of the sentence? Is it just a regular period? Or is it a regex saying we want to match any character? This is where the backslash comes in.
It’s common practice in many coding tools to add a backslash before a character to indicate it should have a meaning different than expected. The problem now becomes: do we add backslashes to the regex?
The seal watch\(ed\|s\) observantly.
or to the normal characters?
The seal watch(ed|s) observantly\.
For historical reasons, basic expressions take the former approach, while extended expressions take the latter.
Navigating a Code Library
In the world of coding there’s a good chance at some point you’ll want to familiarize yourself with someone else’s code library. It’s best when there’s already documentation to explain how the code is organized, but this isn’t always the case. Sometimes you have to create a map for yourself, and regular expressions (and command line tools) can be a great help with that.
For our first two command line tool examples I use the source code from my C++ nik library since I have ownership rights, so there’s no copyright issues in using it here. You aren’t expected to know C++ of course, the idea is to show you how to orient yourself when exploring unfamiliar code landscapes.
For the past few months I have been writing this (and other) curriculum modules. Before that I was working on the nik library, but it’s been so long now and I’ve focused my concentration on other things that I’ve forgotten exactly how I organized it at the time. What’s more, since I left it unfinished, I hadn’t made documentation yet.
In any case, whether it’s an unfamiliar library or one you’ve been away from for a while, a good way to orient or reorient yourself is by ls-ing (listing) the file and folder contents of the main directory:

The subdirectories (folders) are in blue. So far so good, this gives us an initial feel for how big or complex the library might be, but more detailed information would be better.
Find
The find command line tool lets us explore the filesystem to find files and directories. Regexps aren’t necessary to use this tool; we can ask to find all files in every folder and subfolder starting at our current location:

Here, the (.) represents the current directory, and adding the option –type f means “search, but only report the files”:
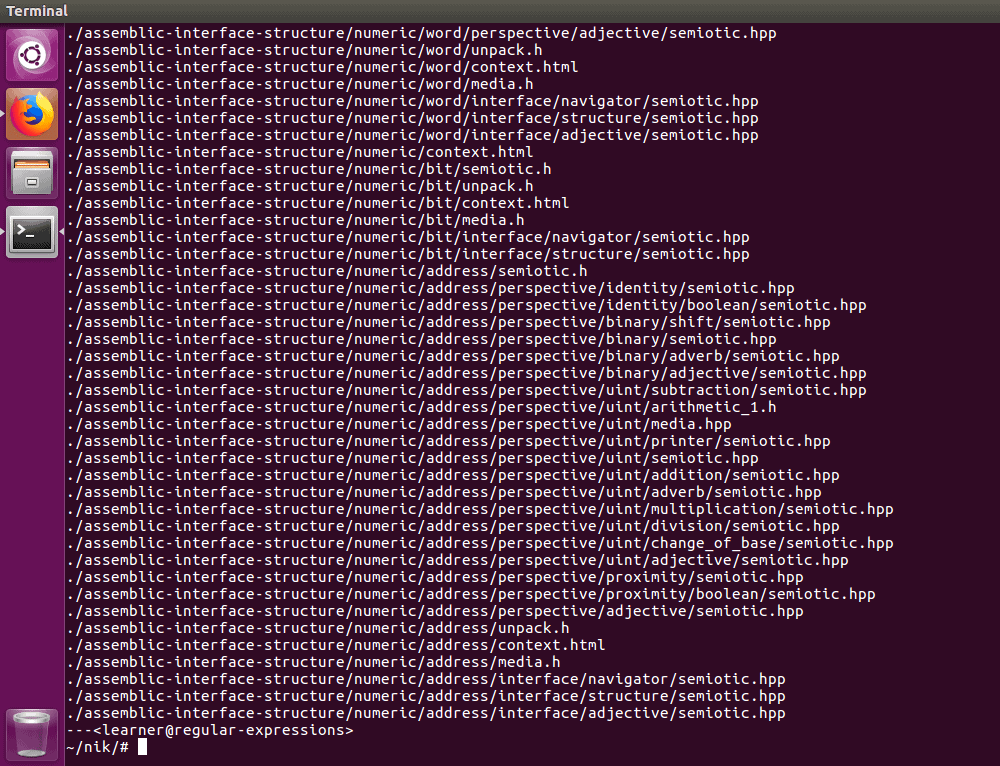
That’s a lot of files! Maybe instead of displaying all the files, we can just get a count:

285 files? That certainly is a lot of files! What I did here was pipe (|) the output of our file command (which is just a page of text), and input it into the wc command which counts words. Adding the -l option changes it to counting lines instead, which is what we’re interested in.
Note: as you may have noticed, a challenging aspect of coding is that many of the same symbols and characters (such as ‘|’) are used by different tools to mean different things. Unfortunately, there’s no way to fix this in a way that would satisfy everyone.
As a quick reminder: if you want to see what options a command line tool has, you can use the man tool…

…to bring up its documentation:
Searching for a Function
Back to our example: I would like to review how I implemented a function called power(…) but have forgotten exactly which file it’s a part of. As there are 285 files, that’s too many to review manually.
So let’s use regular expressions to narrow the field:
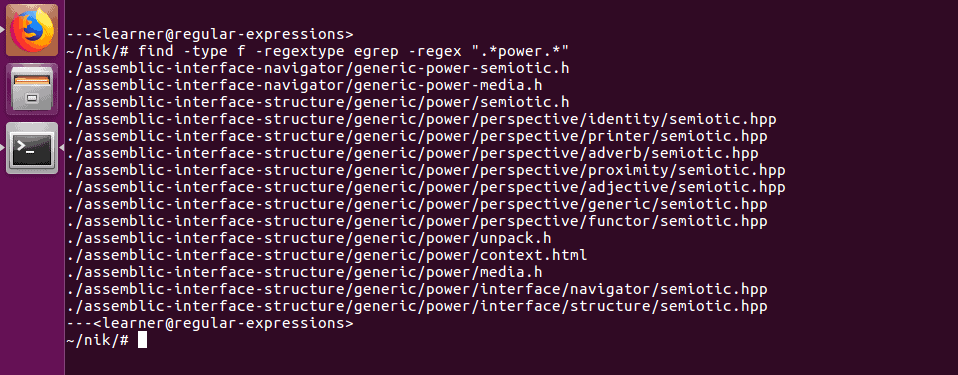
Here I used the find tool restricting our search to files with the -type f option, but I’ve also added the -regextype egrep option to use “grep style” extended expressions. I then used the expression:
-regex “.*power.*”
This expression finds and returns files (searching their path names as well) which have zero or more any characters “.*”, followed by the word “power”, followed again by zero or more any characters “.*”.
Command line tools are expressive enough that they often give you more than one way to do the same thing. If you don’t like adding all those options to the find tool each time, an alternative is:
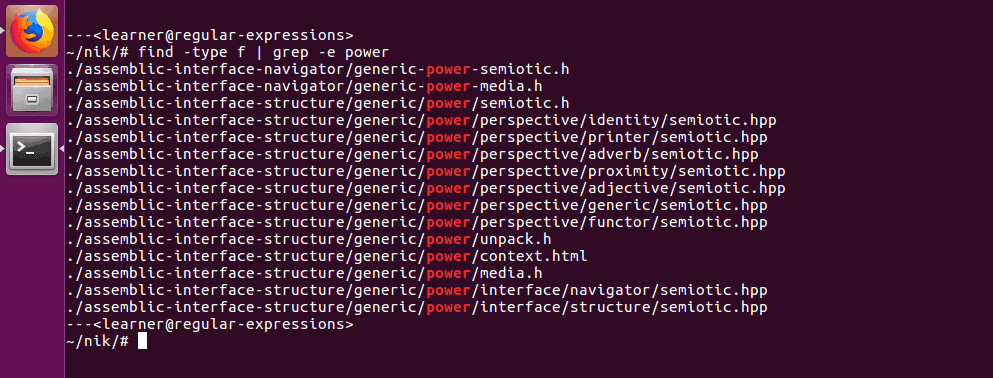
Here we still use find, but return the list of all files (as we did initially), then pipe this into grep, which also uses regular expressions. We don’t have to be so thorough in our regex, because grep simply looks for a match within a line of text and returns the whole line. It also highlights matches in red, which is an additional incentive to use this alternative style of search, as it’s easier to read.
Note: this time I didn’t quote the regex as in previous examples. In Bash if there’s no spaces in your expression or variables (Bash is a programming language), you’re not required to use quotes, though it’s best practice to do so.
Grep
The grep tool is an acronym for “globally search a regular expression and print.” It lets us search individual text files, or recursively all the files in a folder, and returns lines that match.
Our search returned 15 files which is far better than 285, but we still may be able to reduce this further. Instead of searching for files with the word “power” in the file name, let’s look inside the files themselves for this word. As it is also a function, which might have arguments, I’ll narrow our results further by including its parentheses grammar:

Here we are using extended expressions, meaning, if we want to search for the parenthesis characters we need to backslash them. As for the grep options, -E means “use extended expressions”, -r means “search all files recursively” (this way we don’t need to specify which file we want to search), and -e means “what follows is our regular expression.” We could have written the options as:
grep -E -r -e power
But grep allows us to combine them as above. As for the results:
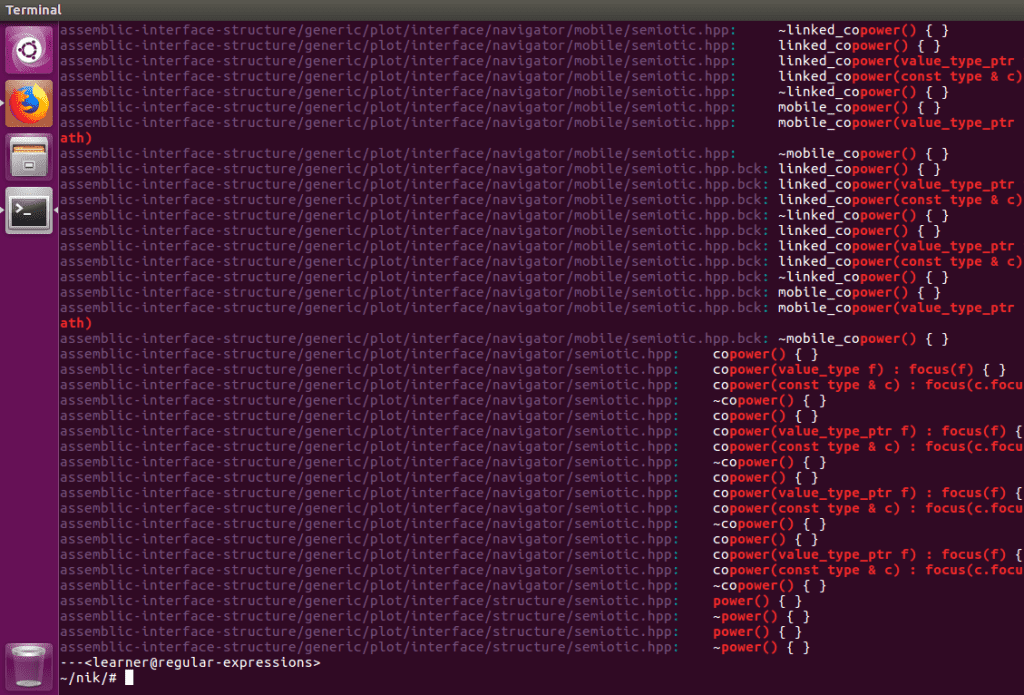
There’s a lot. This search wasn’t as helpful as I had hoped, but that’s okay. Sometimes that’s how it goes. Don’t let a failed attempt stop you; even experienced regex users run into this problem. In any case, we can either abandon this approach and search the initial 15 files by find, or refine the regex and try again. Here I opt for the latter:

I refined the search by ignoring the “copower” matches and included a space before the word “power.” An alternative to filtering out the “copower” matches is to exclude the “co” before the “power” more directly:
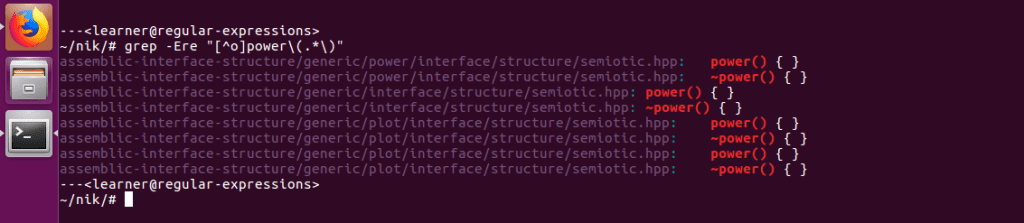
If you begin a character class [char] with a ‘^’, it means exclude. By writing “[^o]” we’re saying exclude the letter ‘o’ before the word “power.” Either way, both of these return much better results than our attempt with find. What’s more, they show the files where the matches occur, as well as the text surrounding the match, which is also helpful.
This concludes the main examples of this demonstration. The most common applications that use regular expressions generally require better knowledge of programming languages or database interfaces. Because of this, I chose to explore my nik library as our example, but it wasn’t an artificial use of regexps: in my own work I often lookup code this way. It’s easy, fast, and accessible.
Finally, even though there are many graphical tools that let you use regular expressions, one nice advantage in using them on the command line is that the tools there were written decades ago under strong hardware constraints (tech was limited at that time). This means that the underlying algorithms implemented tend to be fast and efficient. Don’t take these tools for granted just because they’re old, there are many situations where they perform better than modern ones.
Sed
So far we’ve only looked at searching and navigating our text files, what about editing them?
This is another way in which regular expressions show their power. For example, sometimes I like to look at Inuit traditional stories. One of my favorites is Eskimo Folk-Tales, collected by Knud Rasmussen as he journeyed across the Arctic 100 years ago. This is a good example because the copyright has expired, so these stories are now in the public domain and free to use. Just remember to be respectful, as these stories have a lot of power in them.

If you download the plain text file and view it in your browser, you’ll see it is just one big text file. It has the table of contents from the original book, but in this file there are no distinct pages so it has very little navigational structure.
Let’s say I wanted to edit this book, and split each story into its own text file. How would I do this? I could do it by hand, going into the file, highlighting each story, copying and pasting and saving it, but this is exactly the sort of tedious task computers are much better at. If a computer is going to navigate this file, we need to figure out what markers we can use to separate the stories.
With modern advances in machine learning we could find a way to do this by using the text of the stories themselves, but we’re not ready for that. Besides, it’s a good skill to learn hybrid approaches: sometimes this sort of project is best done as a person-machine collaboration. If convenient markers don’t exist, make them. The first step is to add our own markers.

I chose the following pattern for our markers:
which is similar to html (or xml) tags: I marked the start of a story with a left brace ‘<‘ followed by a number (one or more digits) followed by a right brace ‘>’. To mark the end of the same story I used the same pattern but added a forward slash ‘/’ before the number. You can see this markup by viewing the file in the assets folder called Eskimo-Folk-Tales-indexed.txt.
Note: before adding such markers, it’s best to check to make sure the chosen pattern doesn’t already exist in the file as it would confuse the automation process later on.
Note: I did this markup editing with the vim text editor, which also lets you use regular expressions. Although vim has a steep learning curve, it is worth learning since it helps to automate many text editing processes.
On to the machine component of this project: using the sed command line tool, I searched for each marked-up story and wrote it to its own file:

To be fair, if you’re unfamiliar with using Bash or sed I’m not expecting you to understand this script, as there’s a lot going on here.
The point is to show you it can be done, and requires only a few lines of code. When you run this script, it takes only a second or two to create the separate files. Not only is this faster than doing it manually, it also saves your wrists from repetitive strain. Not everything in life or work should be automated, but if you know when to apply it, then this sort of automation can be very helpful.
Note: my intention is not to scare you away from programming with this example. Most languages aren’t so complicated. Truthfully, I’m using two entirely separate languages (Bash, sed) and intermixing them, which is a strange thing to do in general. Mostly, I just wanted to show you some of the possibilities.
Note: if you decide to develop this style of automated editing as a skill, I recommend as a best practice to make a backup or a copy of your files and/or directories first, before you run your scripts. If there’s a bug in your code, you could accidentally delete important parts of your project. If you make such a mistake but have a backup, you can always restore the original and try again (making another copy of course). Always edit the copy, not the original.
Challenge
The 52 individual text file stories mentioned above are included in the asset folder. In one I used sed to substitute all occurrences of the word dog for qimmiq. In another, I substituted all occurrences for cat. Can you use grep to quickly find which ones?
I’ve also inserted a website link into one of the stories. It doesn’t make sense as part of the story, it’s just there for you to find. I didn’t include the https part to make it more challenging to locate. Can you find it with regexps? I believe you can! Think about the predictable patterns that website urls have.
Conclusion
I hope you now have a better understanding of one of the fundamental tools of search, and how to better build words to navigate, explore, as well as build knowledge maps for digital texts.
For all their power and potency, regular expressions also have their weaknesses. For one, using them is like casting a net, and you don’t want it too wide or too narrow. It takes a bit of practice to learn how to get it just right.
Another thing to consider is that this technology works well for writing systems built on Greek and Roman alphabets, but what about Chinese characters? There are about 200 radicals to start, which are then used to compose full characters in a two dimensional way. Regular expressions don’t easily express this form of word building. They can still be used, but they won’t be as effective.
Acknowledging these limitations, I would like to leave you with one thought provoking idea. In this module we have seen how regular expressions can be used to build words and their grammatical variations, but there’s another way to think of them: in giving us the toolset needed to build patterns of words, regular expressions let us build ideas. Maybe this is their true value: they let us navigate not just words, but ideas themselves.
Pijariiqpunga
Resources
- Introduction to Automata Theory, Languages, and Computation, second edition, by John Hopcroft and Jeffrey Ullman. This book provides a solid introduction to automata theory for the motivated reader, and in relation to this module, the initial chapters on regular expressions and regular languages are helpful.
- RegExr: an online tool to learn, build, and test regular expressions (RegEx / RegExp). It has a nice visual interface with color coding making it easier to visually group patterns.
You might also like

Cultural Sensitivity When Posting Online
 Grade 7 – Grade 12
Grade 7 – Grade 12
Memes can be funny to share with friends and family. But sometimes they are offensive to other cultures. Learn what not to share online and cultural sensitivity.

How The Internet Works: Part 2
Grade 12
In part 2 of the How the Internet Works series we discuss how social problems affect the internet, as well as how we can affect the internet.

How The Internet Works: Part 1
Grade 11 – Grade 12
Learn how the internet works! In here we discuss many topics, as well as provide some resources and examples for you to check out!
